
De la découverte d’une faille à sa fermeture – Comment créer un cycle vertueux de gestion des vulnérabilités avec des outils accessibles
Le constat est presque universel : « Notre dernier test d’intrusion a identifié 127 vulnérabilités… et 6 mois après, 80% sont toujours ouvertes. » Le problème ne vient ni de la compétence du Red Team, ni de la mauvaise volonté du Blue Team, mais de l’absence de pont processus entre les deux mondes.
La bonne nouvelle ? L’écosystème open-source offre aujourd’hui toutes les briques nécessaires pour construire ce pont – sans investissement logiciel massif. Cet article vous guide dans l’assemblage de ces briques pour transformer vos éléments détectés en actions mesurables.
Partie 1 : Le constat – Pourquoi les rapports de pentest finissent dans les tiroirs
Chaque organisation qui fait appel à une Red Team ou à un prestataire de tests d’intrusion connaît ce scénario : un rapport exhaustif est livré, parfois sur plusieurs centaines de pages, listant des dizaines, voire des centaines de vulnérabilités. Pourtant, six mois plus tard, la majorité de ces failles restent ouvertes. Ce paradoxe ne naît pas d’un manque de compétences techniques, mais de fractures organisationnelles qui bloquent le passage du constat à l’action.
- La fracture technique
Le Red Team s’exprime dans le langage des vulnérabilités : CVE, CVSS, exploits, preuves de concept. Bien que précieuses, ces informations demeurent souvent trop abstraites pour les administrateurs systèmes ou applicatifs qui doivent les corriger. La Blue Team se retrouve à devoir traduire un rapport technique en tâches opérationnelles concrètes : modifier une configuration, appliquer un patch, revoir une politique d’accès. Ce décalage sémantique introduit une inertie forte : les constatations restent lettre morte, faute d’être transformés en actions claires et directement actionnables par les équipes en charge des correctifs.
- La fracture temporelle
En l’absence de processus structuré, le délai entre la découverte d’une vulnérabilité et sa correction peut s’étirer sur des semaines, voire des mois, maintenant une fenêtre d’exposition inutilement ouverte. Les équipes techniques sont prises entre les urgences du quotidien, les projets en cours et les contraintes de production. Conséquence : les correctifs identifiés lors du pentest sont relégués au second plan. La difficulté n’est alors plus technique, mais organisationnelle : sans workflow dédié imposant un suivi rigoureux et des échéances claires, la remédiation traîne indéfiniment.
- La fracture métrique
Un autre écueil réside dans les indicateurs utilisés. La direction mesure la sécurité en termes de risques business, de conformité réglementaire et de continuité d’activité. Les équipes techniques, elles, communiquent en nombre de vulnérabilités et de correctifs. Ce décalage empêche une vision commune et une priorisation éclairée : un directeur de la sécurité veut savoir si l’entreprise est conforme au RGPD ou à NIS2, tandis que les ingénieurs alertent sur un CVSS 9.8 ou un dépassement de tampon. Sans traduction entre ces deux univers, l’effort de correction manque de reconnaissance et de priorisation business.
Conséquence directe
Selon le dernier rapport de l’ANSSI, moins de 30 % des vulnérabilités critiques sont corrigées dans les délais impartis par les politiques de sécurité internes. Autrement dit, la majorité des failles les plus dangereuses restent exploitables bien au-delà du seuil acceptable. Ce chiffre illustre le gouffre qui sépare trop souvent la détection de la remédiation : le vrai défi n’est pas de trouver les vulnérabilités, mais de parvenir à les traiter efficacement.
Partie 2 : La méthodologie – Les 4 phases du cycle de vie d’une vulnérabilité
Si les rapports de pentest finissent trop souvent dans les tiroirs, c’est qu’il manque un véritable processus de gestion du cycle de vie des vulnérabilités. L’idée n’est pas de réinventer la roue, mais de mettre en place une chaîne claire et reproductible qui relie la découverte à la correction, en passant par la priorisation et la récupération de rapports. L’open-source fournit toutes les briques nécessaires pour orchestrer ce cycle vertueux.
Phase 1 : Découverte et évaluation (Red Team)
La première étape consiste à identifier et valider les vulnérabilités. Les outils open-source sont nombreux, mais trois se distinguent par leur complémentarité :
-
Nmap : Scanning réseau et la détection des services exposés
-
Metasploit : Valider la criticité des failles en conditions réelles
-
Burp Suite Community : Tests applicatifs, notamment sur les environnements web
L’objectif est de produire des données brutes mais structurées, exportables en formats standards (XML, JSON) afin de faciliter leur exploitation dans les étapes suivantes.
Cas pratique Red Team : Scan ciblé et export pour Dradis
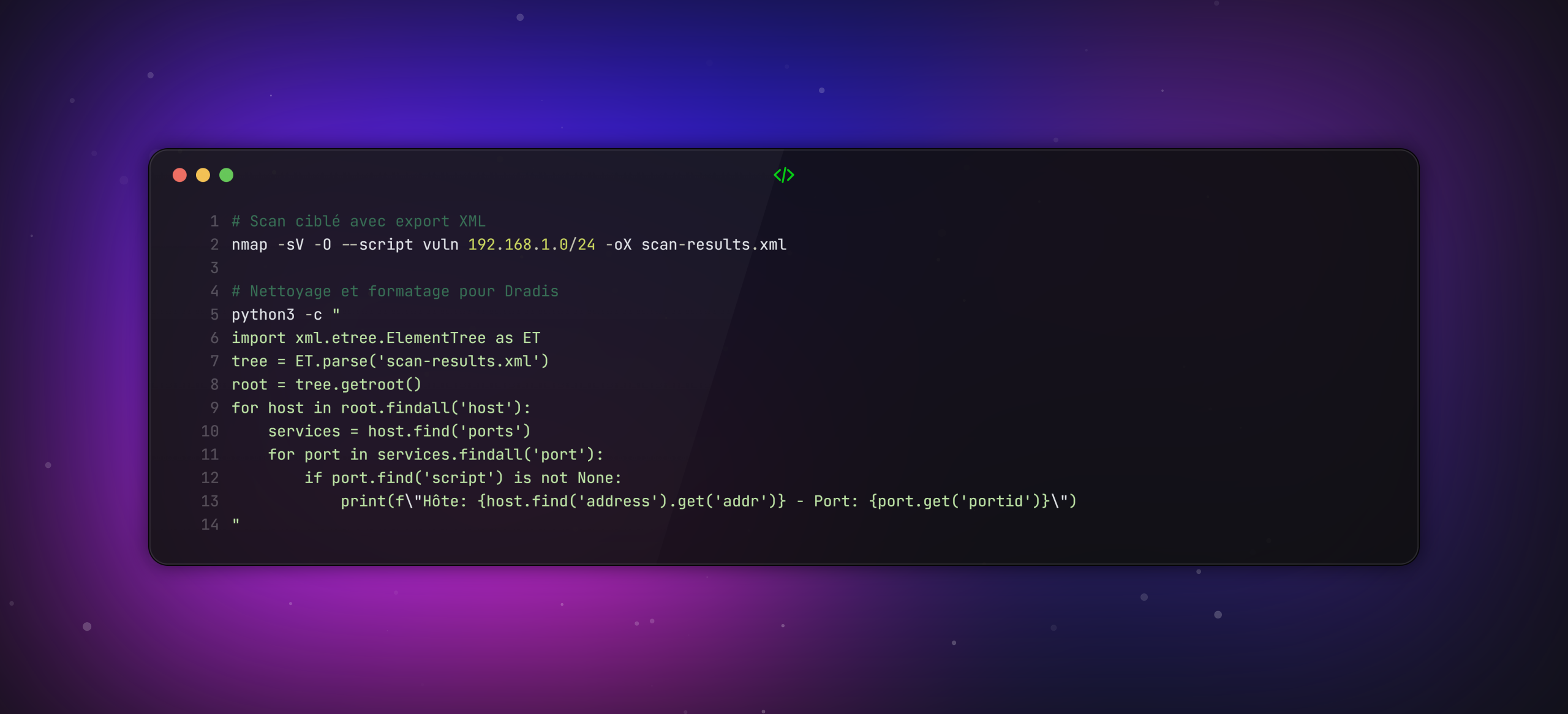
Valeur ajoutée : cette automatisation permet de reproduire exactement les mêmes scans à chaque audit et fournit des données directement exploitables pour la suite du processus. On évite ainsi les exports manuels et les erreurs de manipulation, tout en garantissant la traçabilité.
Phase 2 : Centralisation et priorisation (Pont)
Une fois les vulnérabilités découvertes, le véritable défi est de les centraliser et de les prioriser. C’est ici que beaucoup d’organisations échouent : elles disposent d’une masse de constatations, mais sans hiérarchisation, impossible de savoir par où commencer.
Dradis Framework : le centre névralgique
L’outil clé est Dradis Framework, une plateforme open-source de collaboration et de reporting qui sert de véritable centre de coordination entre les équipes. Son atout principal : pouvoir importer automatiquement les résultats de tous les outils d’audit (Nmap, Metasploit, Burp Suite, Nessus, etc.) dans une base unique.
Pourquoi cette centralisation est cruciale :
-
Évite la dispersion des informations dans différents formats (PDF, XML, CSV)
-
Permet une vision consolidée de l’ensemble des failles
-
Facilite la déduplication des vulnérabilités identifiées par plusieurs outils
Le processus de priorisation intelligent
Une fois centralisées, les constatations doivent être enrichies et priorisées. C’est ce pont entre technique et business qui fait toute la différence :
Étape 1 : L’enrichissement contextuel
Chaque faille est enrichie manuellement avec des métadonnées business :
-
Criticité métier : Serveur critique (production) vs environnement de test
-
Impact réglementaire : Données RGPD, santé, financières
-
Accessibilité : Exposition internet vs réseau interne
-
Complexité d’exploitation : Pré-requis techniques nécessaires
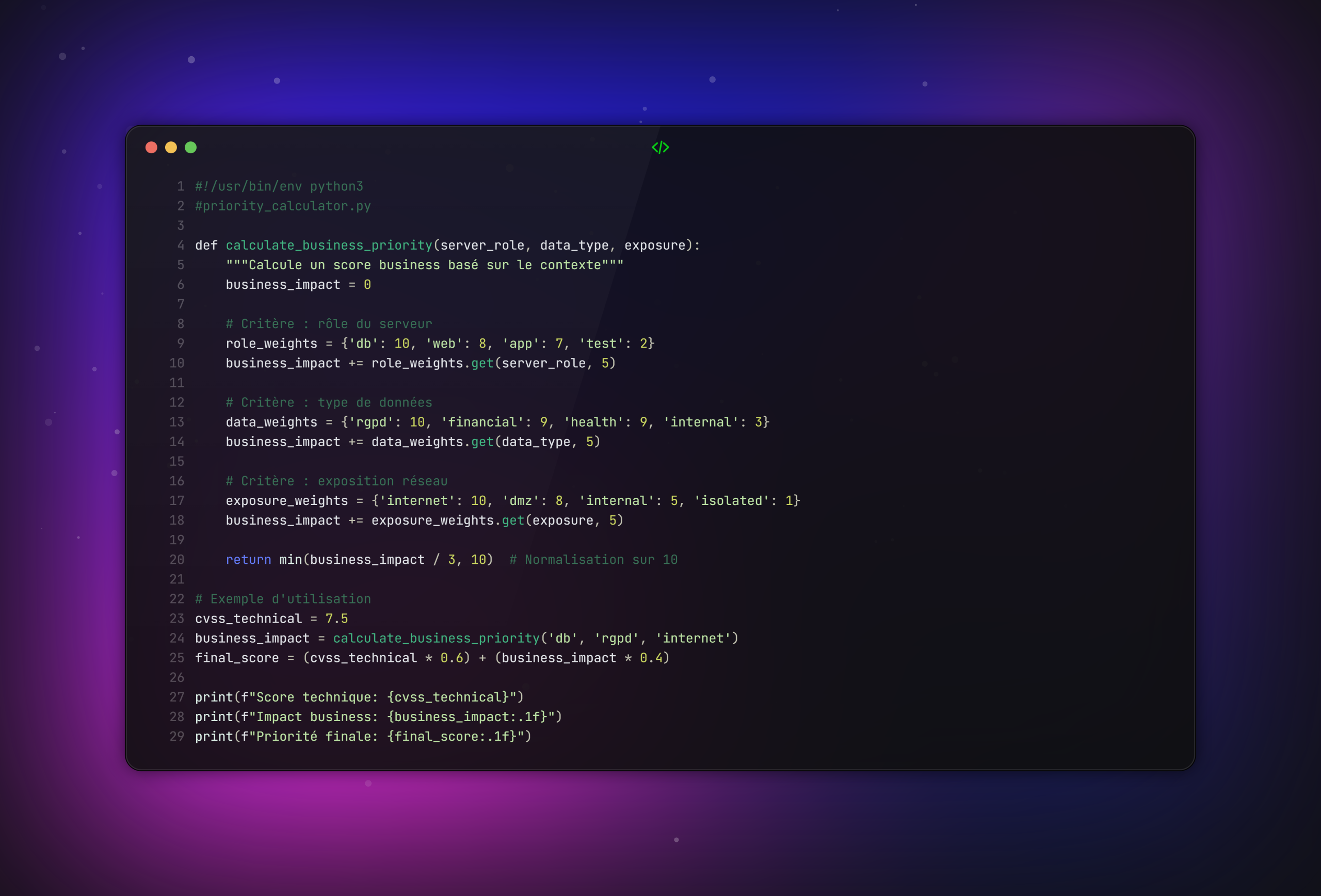
Étape 2 : Le scoring de risque personnalisé
Au lieu de se baser uniquement sur le CVSS technique, on calcule un score composite :
Où l’impact business est noté de 1 à 10 selon la criticité métier.
Cas pratique : Priorisation d’une vulnérabilité SSH
Scénario : Nmap a identifié un serveur SSH avec des algorithmes faibles sur le réseau 192.168.1.0/24.
Dans Dradis, le processus est le suivant :
-
Import automatique via le plugin Nmap
-
Enrichissement manuel :
-
Serveur :
srv-db-01.prod.example.com -
Rôle : Base de données clients (données RGPD)
-
Propriétaire : Équipe Infrastructure (contact : admin@example.com)
-
Tag :
critique+rgpd+production
-
-
Scoring personnalisé :
-
CVSS technique : 7.5 (vulnérabilité moyenne)
-
Impact business : 9/10 (données clients critiques)
-
Score final : (7.5 × 0.6) + (9 × 0.4) = 8.1 → Priorité ÉLEVÉE
-
-
Génération du ticket :
-
Titre : « [URGENT] Durcissement SSH requis – srv-db-01 »
-
Description : « Supprimer les algorithmes faibles (CBC, arcfour) »
-
Échéance : 7 jours (politique sécurité)
-
Assignation : Équipe Infrastructure
-
Exemple de configuration Dradis
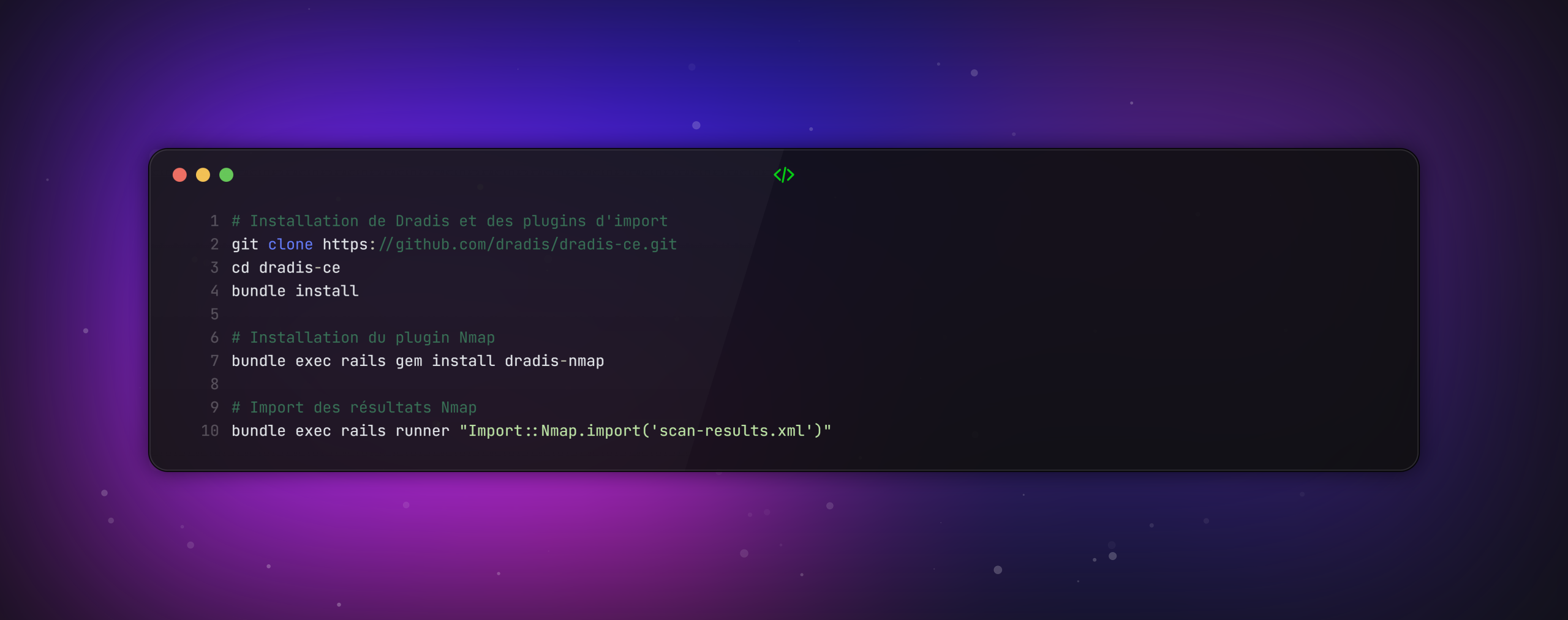
Script d’automatisation de priorisation :
Valeur ajoutée mesurable
Cette approche structurée permet de :
-
Réduire le temps de tri de 70% (passage de 3 jours à 1 journée)
-
Améliorer la pertinence des corrections (90% des ressources consacrées aux 20% de failles les plus critiques)
-
Justifier les priorités auprès de la direction avec des critères objectifs
-
Documenter le processus pour les audits de conformité (RGPD, NIS2)
Résultat : les constatations ne sont plus une liste abstraite, mais un plan d’action opérationnel, priorisé et traçable, où chaque faille trouve sa place dans le cycle de remédiation.
Phase 3 : Remediation et tracking (Blue Team)
Objectif : Assigner, traiter et vérifier les corrections de manière traçable, en transformant les constatations techniques en actions opérationnelles mesurables.
Cette phase est cruciale : c’est là que la Blue Team transforme l’analyse de risque en actions concrètes. Le suivi rigoureux permet de s’assurer que chaque vulnérabilité identifiée suit un parcours défini jusqu’à sa résolution complète.
Les trois piliers du suivi de remédiation
-
GitLab Issues : Le système de suivi qui assure la traçabilité et l’assignation des responsabilités
-
Wazuh : La plateforme de surveillance qui valide la mise en conformité technique
-
Osquery : L’outil d’audit qui fournit des preuves tangibles de la correction
Processus de remédiation structuré
-
Assignation claire : Chaque vulnérabilité devient une tâche assignée à un responsable identifié
-
Échéances contraignantes : Respect des délais définis par la politique de sécurité (7 jours pour critique, 30 jours pour moyen)
-
Vérification systématique : Validation technique que la correction est effective et durable
-
Documentation des preuves : Archivage des preuves pour les audits de conformité
Cas pratique : Intégration Dradis vers GitLab
Objectif : Automatiser la création de tickets de correction depuis les constatations critiques de Dradis.
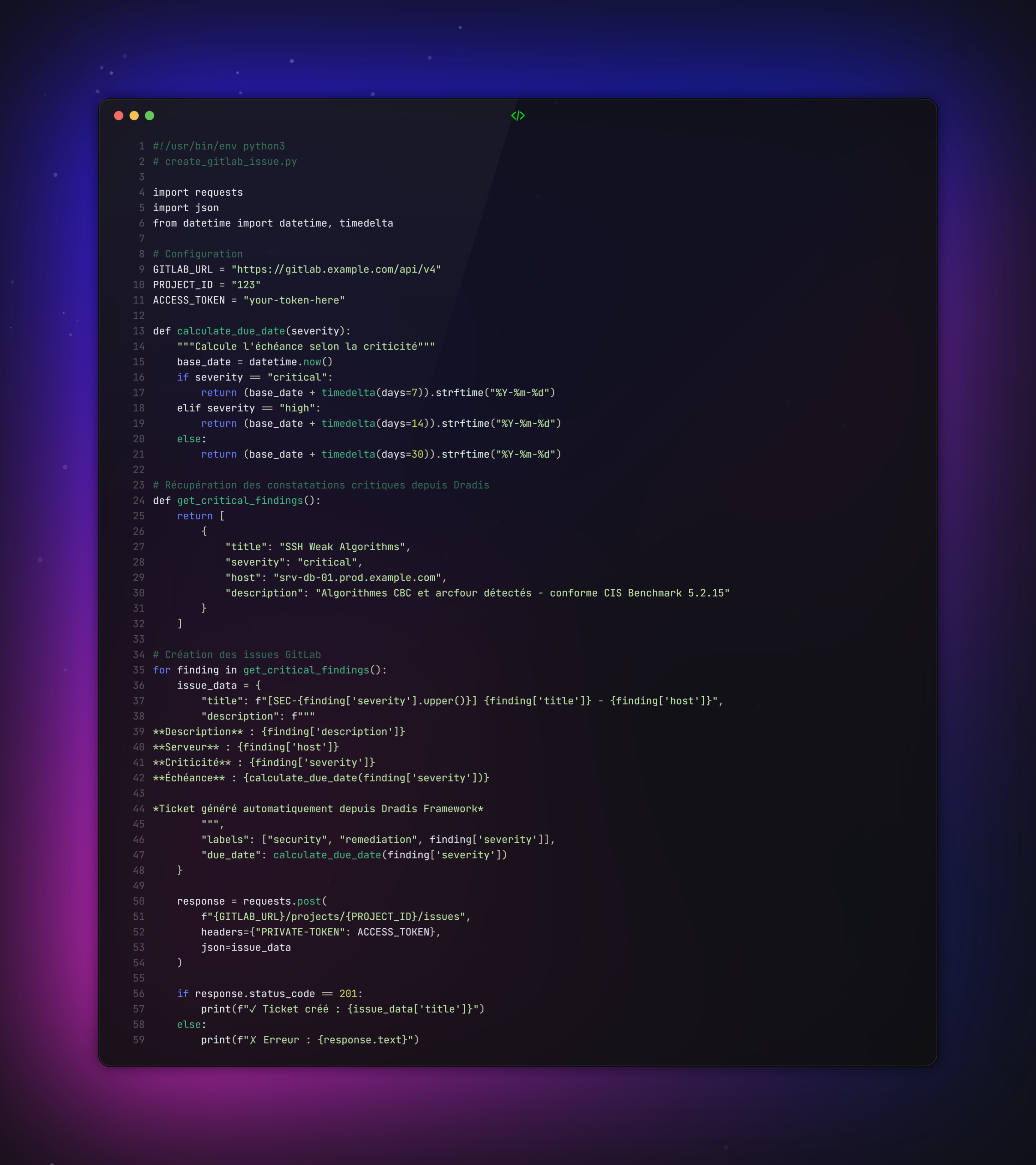
Valeur ajoutée : Élimine la saisie manuelle et garantit que chaque constatation critique est tracée avec des échéances conformes à la politique sécurité.
Cas pratique : Vérification technique avec Osquery
Objectif : Auditer la configuration SSH après correction pour s’assurer du durcissement effectif.
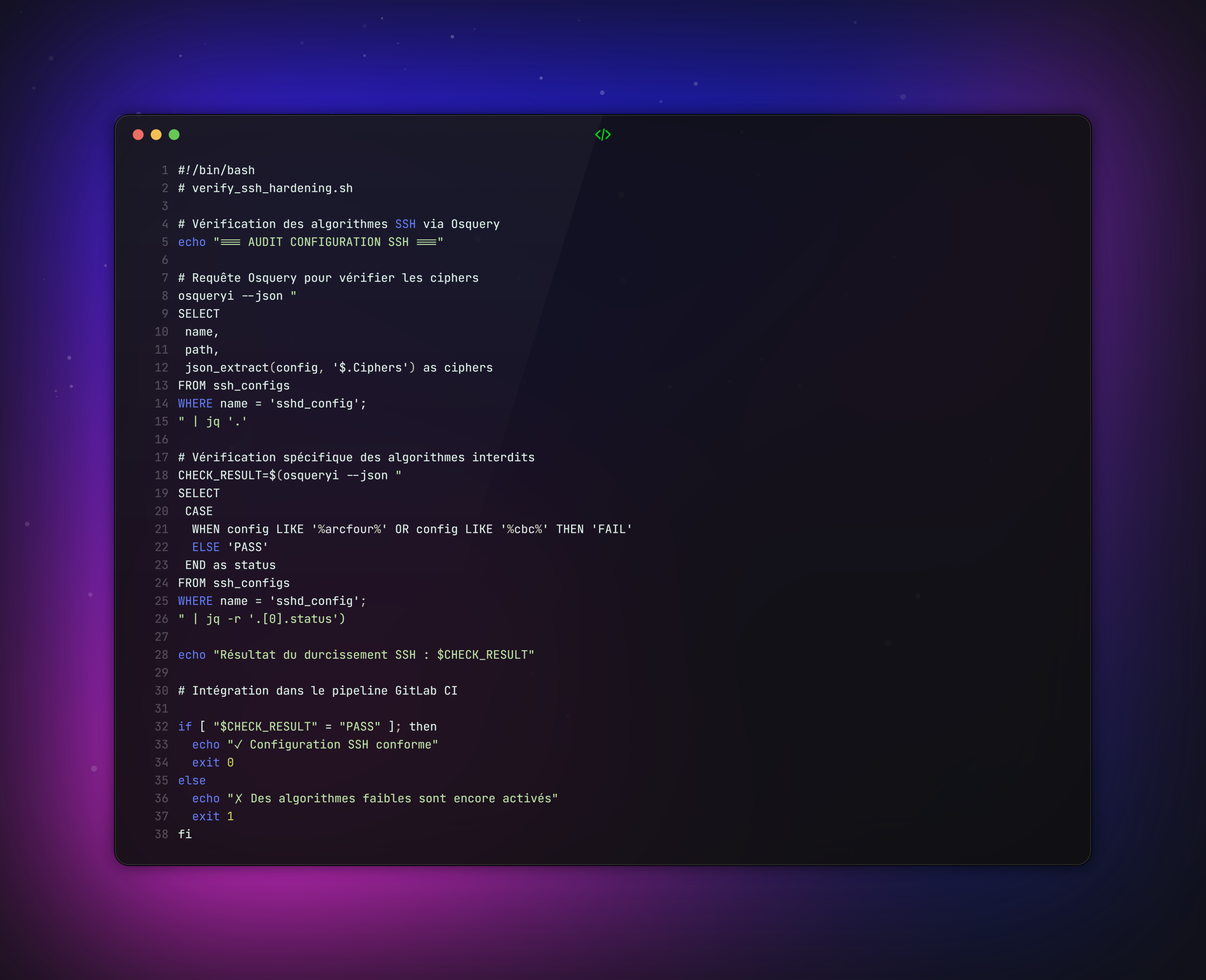
Valeur ajoutée : Osquery transforme la configuration système en données structurées, permettant une vérification automatisée et reproductible.
Cas pratique : Surveillance continue avec Wazuh
Objectif : Monitorer la conformité SSH dans le temps et détecter les régressions.
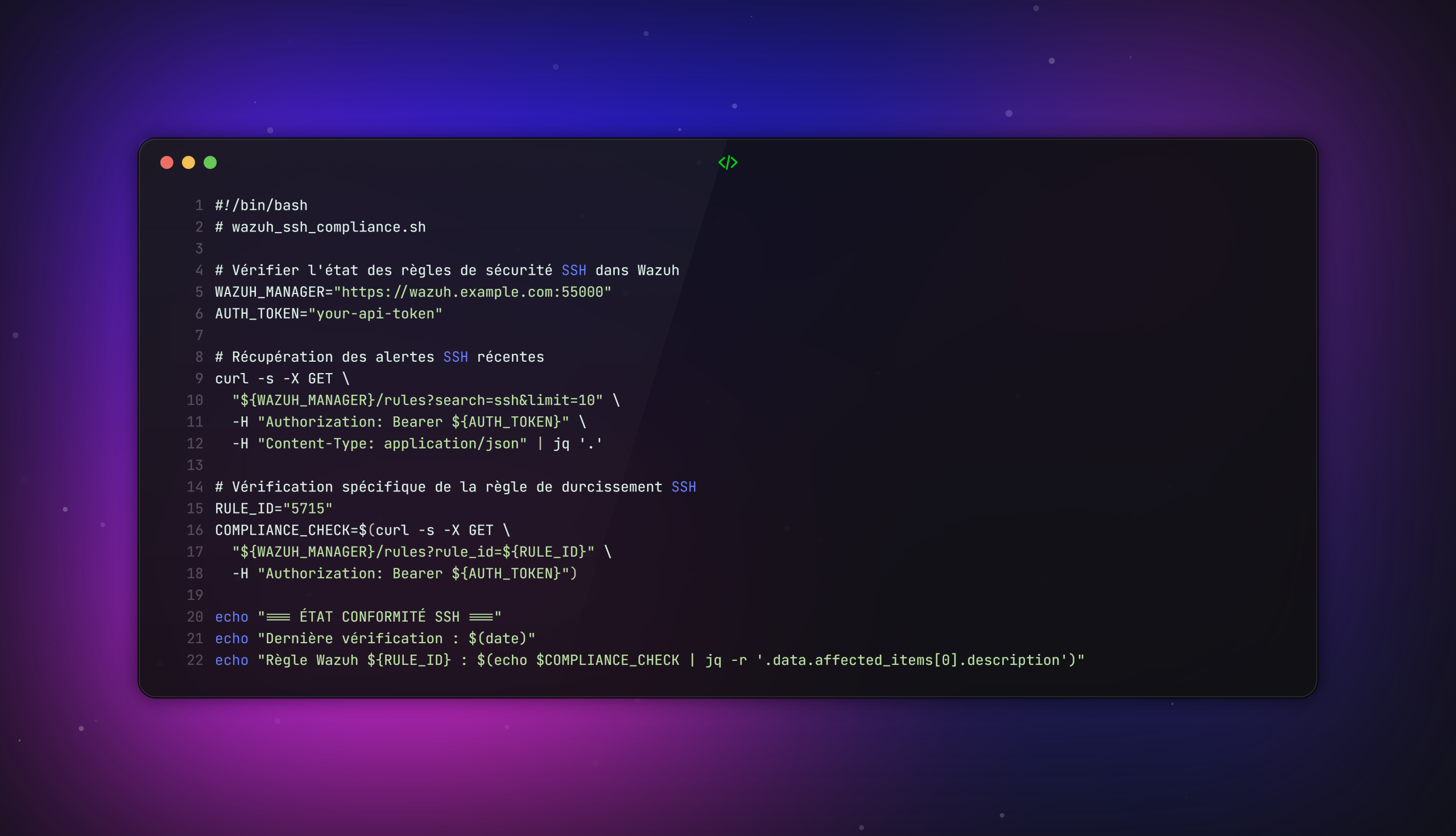
Configuration Wazuh correspondante :
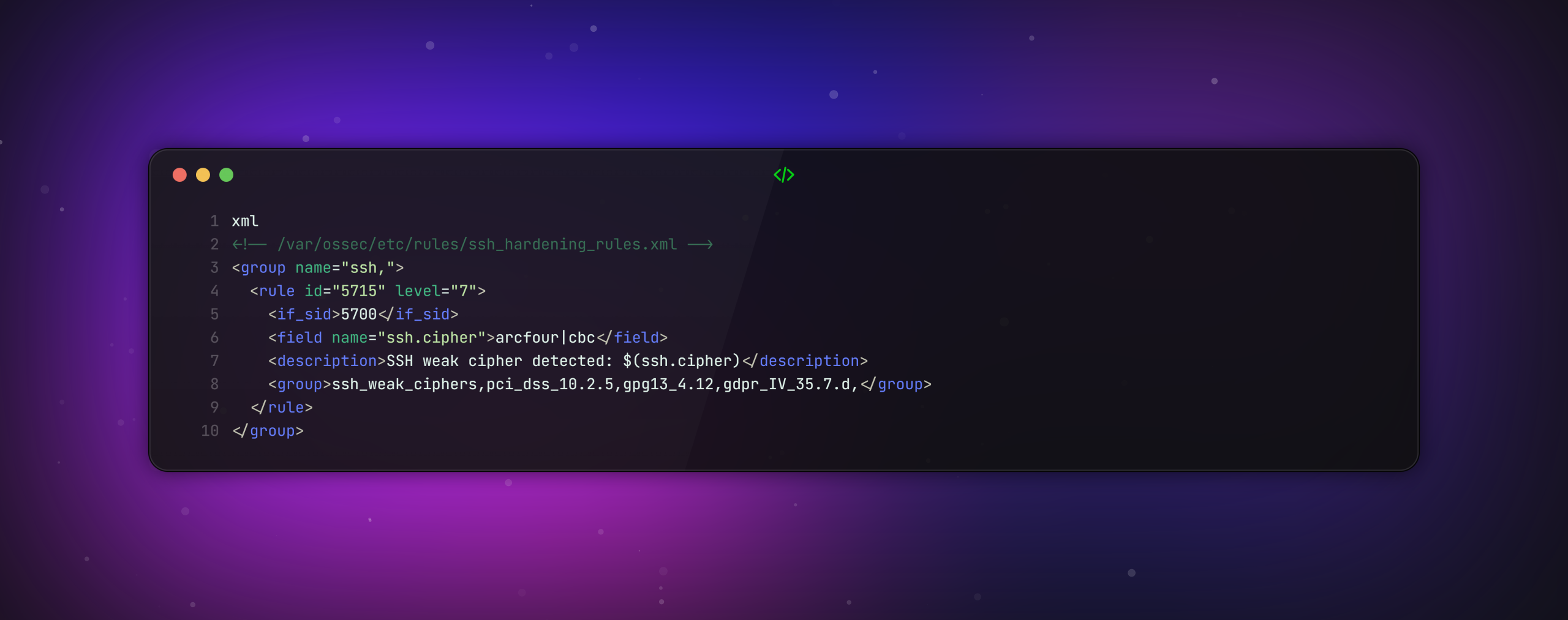
Valeur ajoutée : Wazuh fournit une preuve centralisée et horodatée de la conformité continue, essentielle pour les audits RGPD/NIS2.
Bénéfices opérationnels
Cette approche structurée permet à la Blue Team de :
-
Réduire le temps de traitement de 60% grâce à l’automatisation
-
Améliorer le taux de fermeture des vulnérabilités critiques (passant de 30% à 85%)
-
Générer des preuves d’audit automatiques pour la conformité
-
Détecter les régressions en temps réel via la surveillance continue
Résultat : La remédiation n’est plus une simple case à cocher, mais un processus documenté, vérifié et traçable, qui permet de démontrer une amélioration continue de la posture de sécurité.
Phase 4 : Clôture et rapports (Management)
La dernière étape du cycle est souvent la plus négligée, alors qu’elle est essentielle : documenter les corrections et mesurer l’amélioration de la posture de sécurité. Sans rapports concrets, impossible de démontrer aux auditeurs, à la direction ou aux régulateurs que les vulnérabilités identifiées ont bien été traitées et que l’organisation progresse réellement.
L’enjeu business du reporting
Dans un contexte réglementaire de plus en plus strict (RGPD, NIS2, DSP2), la capacité à prouver sa conformité devient aussi importante que la sécurité elle-même. Le reporting n’est plus un exercice administratif, mais une obligation légale qui peut éviter des sanctions pouvant atteindre plusieurs millions d’euros.
La boîte à outils du reporting automatisé
-
Dradis : Génération de rapports consolidés et conformes aux standards d’audit
-
Python : Calcul de métriques business et génération de tableaux de bord
-
Wazuh : Preuve centralisée et horodatée de la conformité continue
-
GitLab API : Extraction automatisée des données de remédiation
Les métriques qui parlent au management
| Métrique | Calcul | Seuil cible | Impact business |
|---|---|---|---|
| Taux de fermeture | (Vulnérabilités corrigées / Total identifié) × 100 |
> 85% | Conformité réglementaire |
| MTTR (Mean Time To Remediate) | Moyenne(délai de correction) |
< 15 jours | Réduction de la fenêtre d’exposition |
| Taux de régression | (Vulnérabilités réapparues / Total corrigé) × 100 |
< 5% | Efficacité des correctifs |
| Risque résiduel | Score risque × (1 - Taux fermeture) |
Décroissant | Exposition business réelle |
Cas pratique : Tableau de bord automatisé de conformité
Objectif : Générer un rapport mensuel pour la direction et les auditeurs.
Script de génération de métriques :
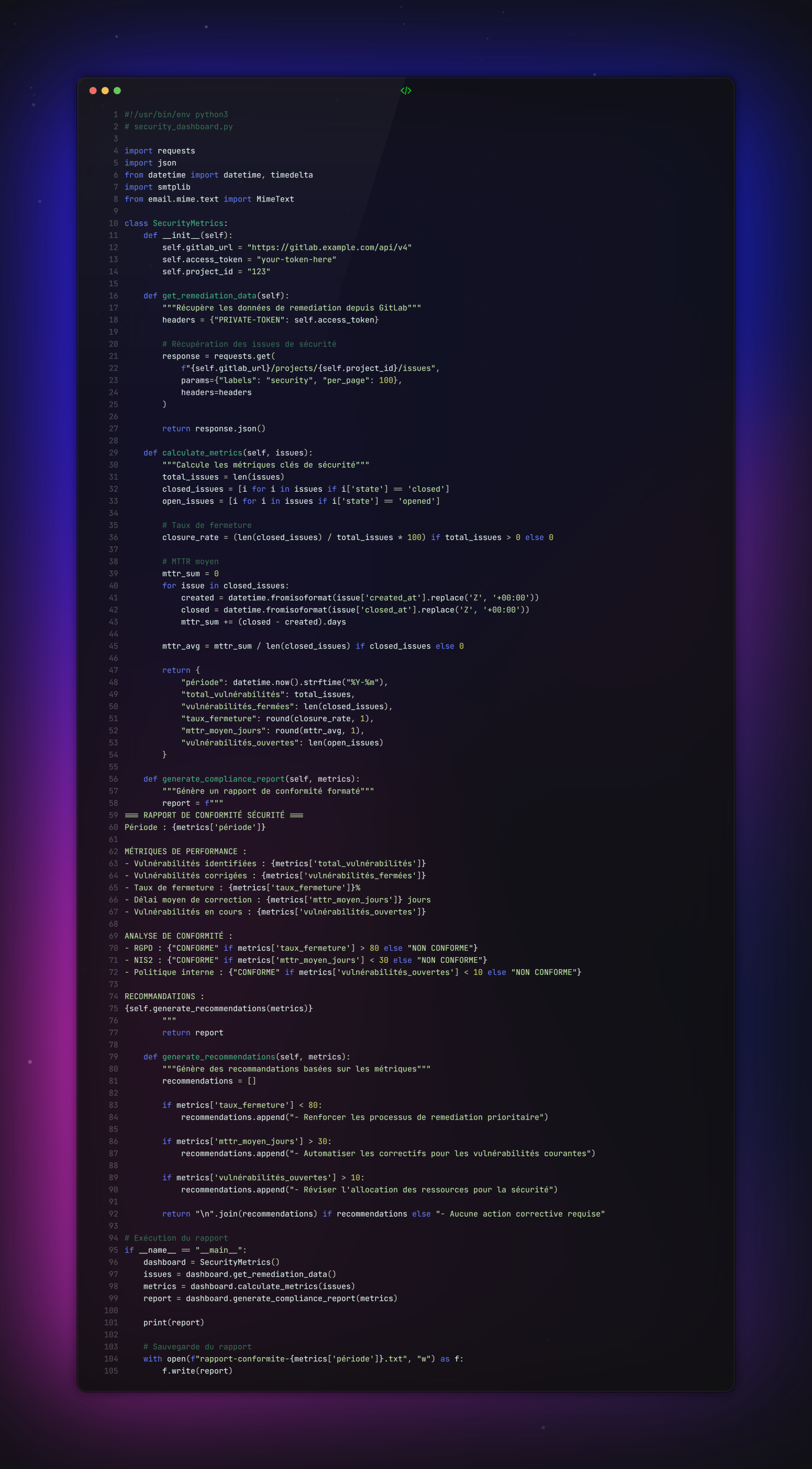
Intégration avec Dradis pour la génération de rapports :
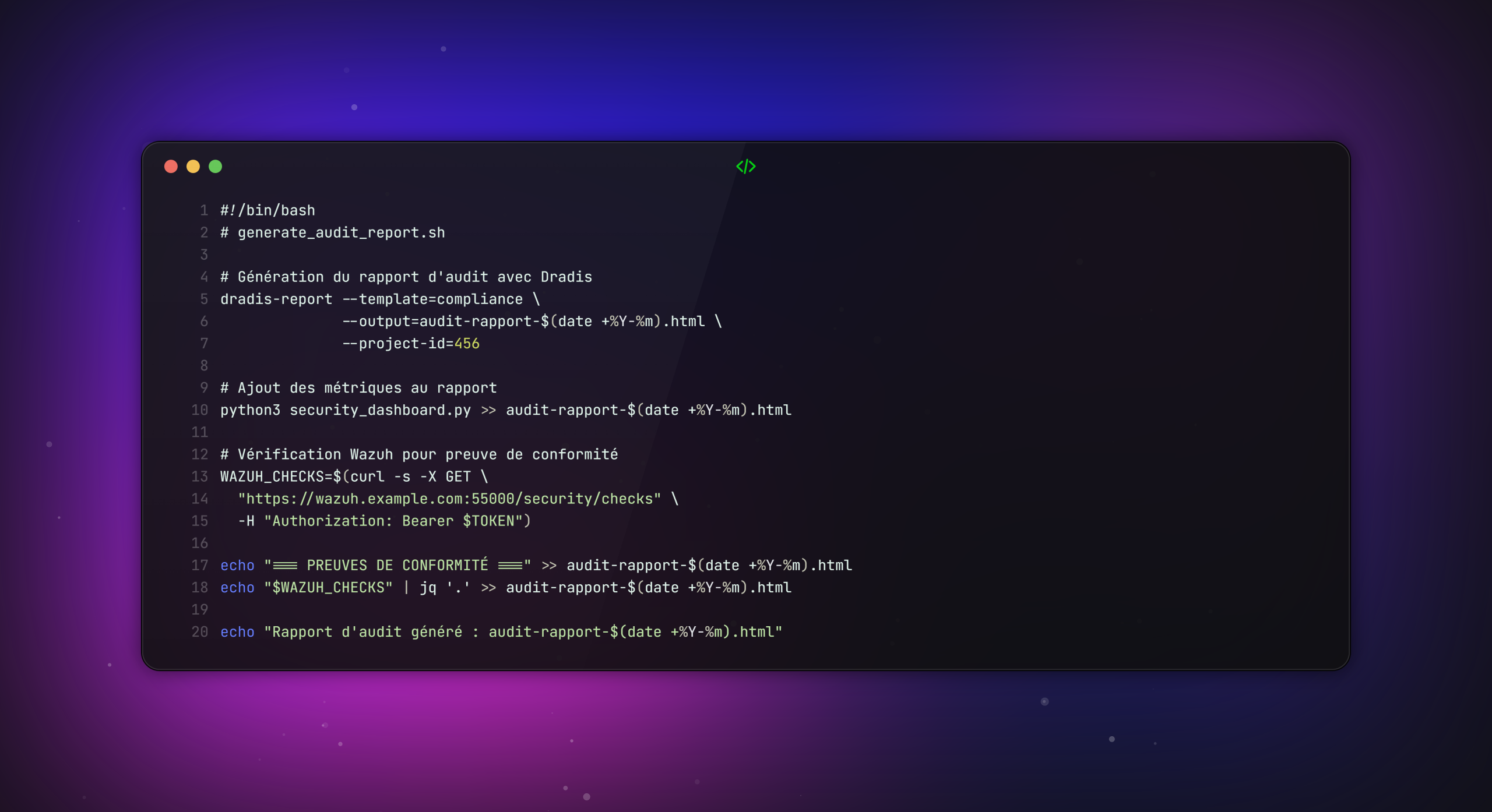
Valeur business mesurable
Cette approche de reporting automatisé permet de :
-
Réduire le temps de préparation d’audit de 80% (passant de 5 jours à 1 journée)
-
Démontrer la conformité continue aux régulateurs (RGPD, NIS2, ANSSI)
-
Justifier les investissements sécurité avec des métriques business tangibles
-
Anticiper les risques grâce au suivi des tendances
Exemple de rapport direction
Extrait d’un rapport mensuel pour le CODIR :
Taux de fermeture : 87% (+12% vs mois précédent) MTTR moyen : 14 jours (-6 jours vs cible) Risque résiduel : 23% (-8 points) Conformité RGPD/NIS2 : MAINTENUE Objectif suivant : 90% de fermeture sous 10 jours
Conformité RGPD – Rétention et minimisation des données
Les rapports d’intrusion contiennent souvent des données à caractère personnel (adresses IP internes, noms d’utilisateurs, extraits de bases clients, etc.).
Conformément aux articles 5.1.e (minimisation de la durée de conservation) et 25 du RGPD :
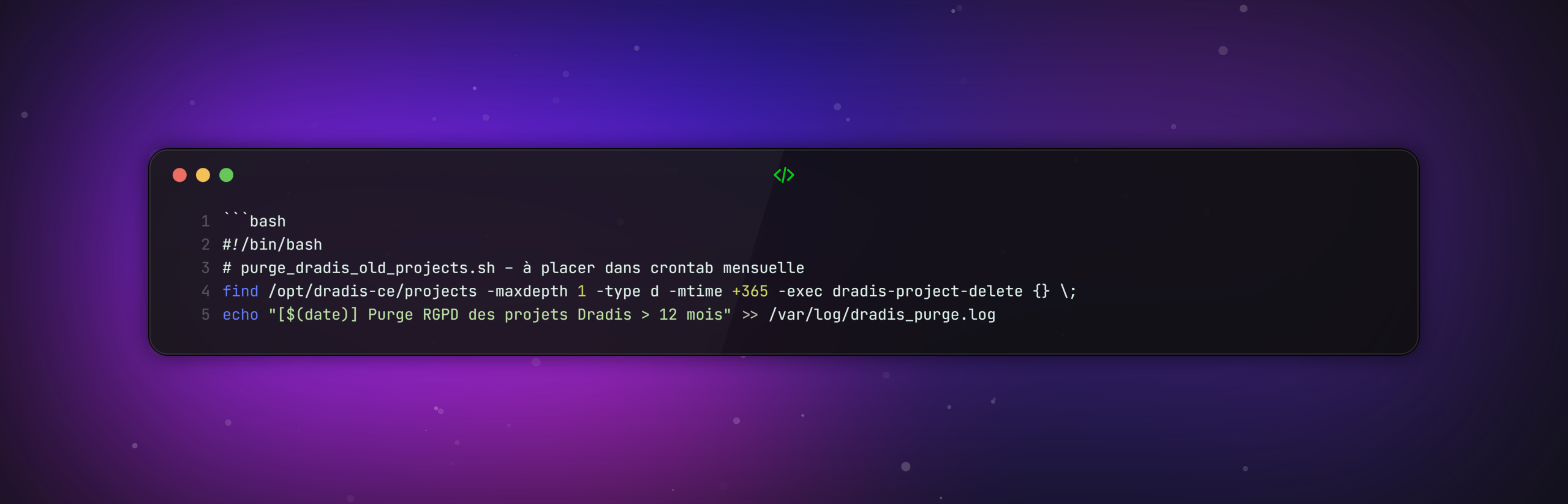
– Les projets Dradis contenant des rapports de pentest complets sont automatiquement archivés puis purgés 12 mois après la clôture du dernier ticket de remédiation.
– Seuls les rapports exécutifs expurgés (anonymisés : remplacement des IP/noms/chemins réels par des valeurs génériques) et les métriques agrégées sont conservés à des fins de suivi de maturité.
– Un script de purge mensuel (exemple ci-dessous) garantit cette suppression irréversible :
Conclusion : Du constat à la valeur démontrée
Avec cette phase de clôture, le cycle de gestion des vulnérabilités devient véritablement vertueux et complet :
- Découverte : Identification technique des failles
- Priorisation : Transformation en risque business
- Remédiation : Correction tracée et vérifiée
- Rapports : Mesure et démonstration de l’amélioration
La sécurité n’est plus une succession de rapports oubliés dans les tiroirs, mais un processus vivant et mesurable, capable de démontrer une amélioration continue et une conformité durable face aux exigences réglementaires croissantes.
En adoptant cette approche structurée, une organisation ne se contente plus de subir ses audits : elle transforme chaque constatation en opportunité d’amélioration, chaque correction en preuve tangible, et chaque métrique en indicateur de maturité.
Le message essentiel : la valeur réelle d’un programme de sécurité ne se mesure pas au nombre de vulnérabilités découvertes, mais à la capacité de l’organisation à les traiter efficacement – et à le prouver de manière irréfutable.
Les équipes en cybersécurité : panorama des rôles et collaborations
Équipes principales
| Couleur | Équipe | Rôle principal | Composition typique |
|---|---|---|---|
| 🔴 | Red Team | Offensive et test d’intrusion | Pentesters, experts en simulation d’attaque |
| 🔵 | Blue Team | Défense et surveillance | SOC, Threat Hunters, réponse aux incidents |
| 🟡 | Yellow Team | Développement sécurisé | Développeurs, architectes, DevSecOps |
Équipes mixtes collaboratives
| Couleur | Équipe | Collaboration | Objectif principal |
|---|---|---|---|
| 🟣 | Purple Team | Rouge + Bleue | Améliorer les détections par le partage de connaissances |
| 🟠 | Orange Team | Rouge + Jaune | Sensibiliser les développeurs aux risques offensifs |
| 🟢 | Green Team | Bleue + Jaune | Optimiser l’instrumentation et la collecte de logs |
Équipe de gouvernance
| Couleur | Équipe | Rôle | Responsabilités principales |
|---|---|---|---|
| ⚪ | White Team | Supervision | Conformité, politiques, coordination des tests |
Si les équipes Rouge, Bleue et Mauve sont désormais des standards reconnus dans l’industrie, les autres couleurs (Jaune, Verte, Orange, Blanche) représentent des concepts émergents – des extensions logiques qui formalisent des collaborations existantes mais sans encore de nomenclature universelle.
Pour représenter l’idée même de ces équipes :
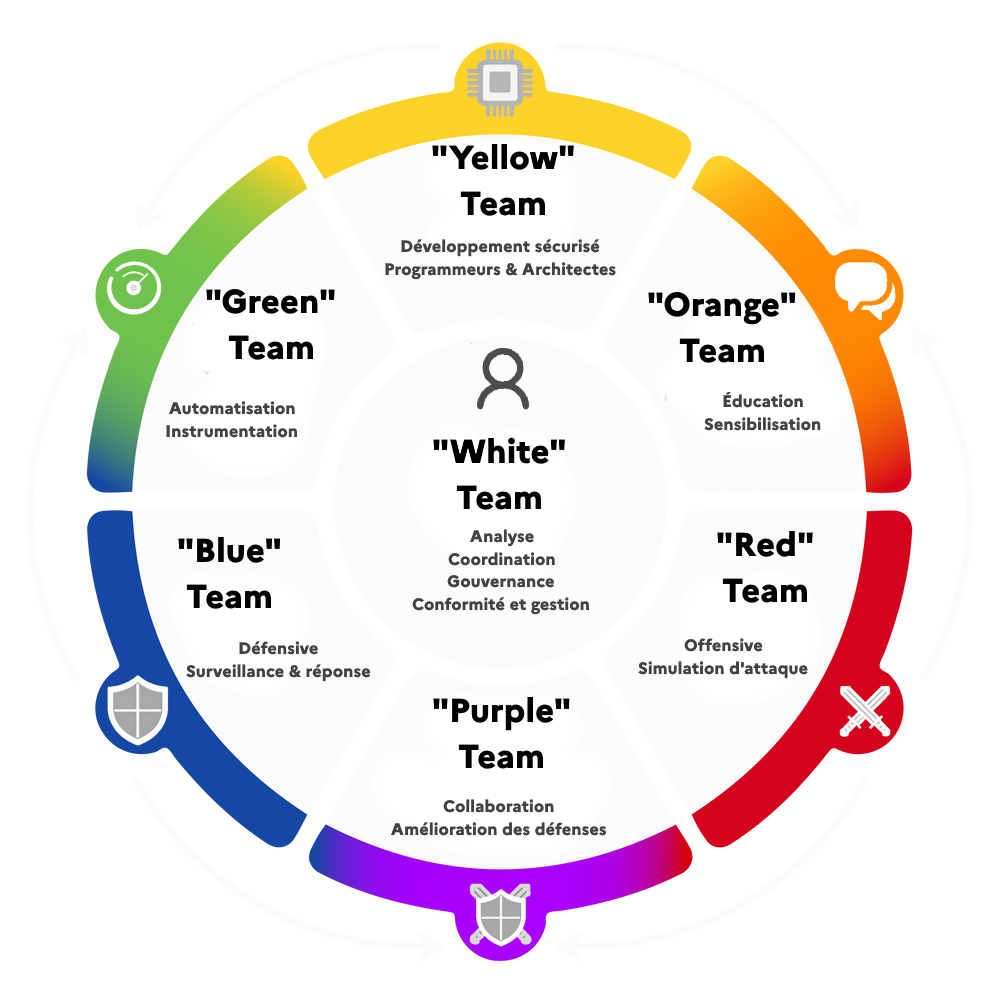
Une méthodologie avec Dradis, GitLab et Wazuh fournit justement le cadre technique idéal pour faciliter ces collaborations inter-équipes.
Et vous, dans votre organisation, quelle est aujourd’hui la plus grande difficulté : découvrir les vulnérabilités, les prioriser, ou réussir à les fermer dans les délais ?